
Oi está aqui!!!
http://alfresco.ambientelivre.com.br:8080/share/s/4ulqp1vmSWuJDMbRMl5fbQ
Uma maquina de testes pode ser baixada :
https://developer.microsoft.com/pt-br/windows/downloads/virtual-machines/
Depois baixar o Bizage do site Oficial da Empresa.
https://www.bizagi.com/pt/plataforma/modeler
tem que fazer un cadastro padrão para spans e marketing. rsrs
 Olá Pessoal, mais uma excelente vaga para Consultores de ETL com Pentaho Data Integration em São Paulo, conversando com um ex-aluno no Linkedin o mesmo me informou sobre uma vaga para consultor de ETL e compartilho aqui com vocês analisarem. Aqueles que passaram por nossas formações de Pentaho Data Integration conseguem atender com tranquilidade os requisitos, basta ter se dedicado com o uso após aprende-lo em cases reais, então segue informações sobre a vaga e boa sorte!
Olá Pessoal, mais uma excelente vaga para Consultores de ETL com Pentaho Data Integration em São Paulo, conversando com um ex-aluno no Linkedin o mesmo me informou sobre uma vaga para consultor de ETL e compartilho aqui com vocês analisarem. Aqueles que passaram por nossas formações de Pentaho Data Integration conseguem atender com tranquilidade os requisitos, basta ter se dedicado com o uso após aprende-lo em cases reais, então segue informações sobre a vaga e boa sorte!
Quem ainda não conhece a ferramenta Open Source mais utilizada no mundo para integração de dados conheça o nosso treinamento em Pentaho Data Integration.
Atuar na construção e sustentação de ETL em Pentaho para a área de BI, ajudando a construir indicadores para diversas áreas da Cia.
Oferecemos:
Zona Leste / SP
Se você quer trabalhar em uma empresa multinacional ágil, com um bom clima de trabalho, que vem crescendo de forma acelerada e que lhe proporcionará plano de carreira você está lendo o anúncio certo para você. #VemSerBeijaflore!
A Beijaflore é uma consultoria de origem francesa fundada em 2000 com presença global atuando na Ásia-Pacífico, América e Europa.
O Grupo Beijaflore conta com mais de 1.000 profissionais experientes atuando no segmento de Tecnologia, Consultoria, Engenharia e Outsourcing, tendo como services lines: Cyber Risk & Security, Data Management , Telecom e IT Infraestrura, Performance & Innovation eCompetitive Strategy.
Para saber mais, acesse: www.beijaflore.com. ;
Somos uma consultoria empresarial francesa, fundada em 2000. Nossa missão consiste em guiar empresas em seus projetos de transformação digital e ajudá-las a modelar o futuro. Globalmente são mais de 1000 talentos apoiando grandes corporações.
A Beijaflore Brasil atua no país com escritórios em São Paulo e Rio de Janeiro, desenvolvendo projetos em todo território nacional. Oferecemos quatro linhas de serviço com ofertas complementares em consultoria de negócios e tecnologia: Performance e Innovation; Cyber Security; Technology e Engineering.
https://beijaflore.gupy.io/jobs/148649?jobBoardSource=gupy_public_page
 Mais uma vaga no Vale do Pinhão para Engenheiro de Dados passada por um parceiro, atenção alunos das MBAs que ministrei aulas este ano, os requisitos passados em sala estão presentes 🙂 Hive, Spark, Machine Intelligence com todos algoritmos do Pentaho Machine Intelligence, e não falei que o Apache Zeppelin ia superar o Jupyter para Data Science, bom enfim estou só comprovando que tudo que estudamos são requisitos fundamentais para o mercado de trabalho!
Mais uma vaga no Vale do Pinhão para Engenheiro de Dados passada por um parceiro, atenção alunos das MBAs que ministrei aulas este ano, os requisitos passados em sala estão presentes 🙂 Hive, Spark, Machine Intelligence com todos algoritmos do Pentaho Machine Intelligence, e não falei que o Apache Zeppelin ia superar o Jupyter para Data Science, bom enfim estou só comprovando que tudo que estudamos são requisitos fundamentais para o mercado de trabalho!Quem superou esta fase esta abaixo a Vaga! Boa Sorte!
HABILIDADES/COMPETÊNCIAS:
O Programa RemoveMessageOpenFire foi desenvolvido para auxiliar no processo de exclusão de conversas do banco de dados do Servidor OpenFire, Inicialmente ele tem suporte a base nativa do OpenFire que é o HSQLDB.
Como este banco de dados e pouco comum entre a maioria dos administradores de sistemas , este programa foi criado para auxilio deste processo o deixando prático e fácil de execução.
Realize o Download de https://github.com/marciojv/RemoveMessageOpenFire/blob/master/RemoveMessageOpenFire.sh
Como usar:
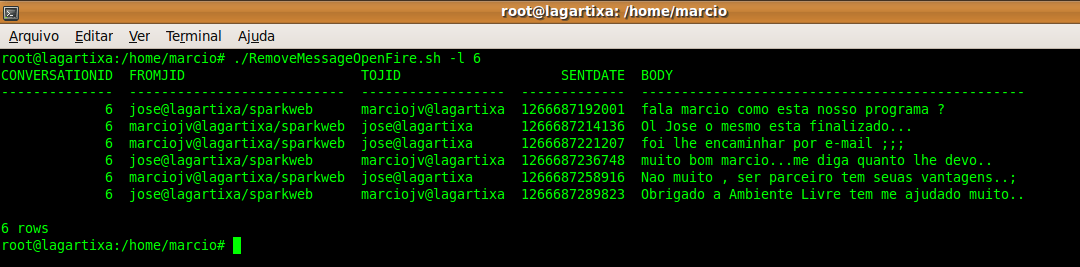

Características do Programa
– Requisitos
Ter java no Ambiente, como o OpenFire também exige Java este requisito sempre será previamente atendido
– Desenvolvimento
Desenvolvido em Shell Script chamando as ferramentas nativas de SQL do HSQLDB.
– Desenvolvedor
Marcio Junior Vieira
– Licença
GPL 3
Spark é um software de código aberto, multi-plataforma cliente IM otimizado para empresas e organizações.
Ele possui suporte embutido para o grupo de bate-papo, integração de telefonia, e uma forte segurança.
Também oferece uma experiência do usuário final com características como grande em linha verificação ortográfica, sala de chat em grupo de favoritos, e as conversas por abas.
O Spark é fácil de instalar e basta que o usuário execute o arquivo baixado e siga as
instruções para concluir o processo. Depois é só rodar o programa.

O visual do Spark é atraente e incrivelmente leve. Apesar dos gráficos simples, a interface é
bem elaborada e oferece um ótimo desempenho. Aliás, pode-se dizer que o equilíbrio entre
desempenho, visual e recursos é o que mais chama a atenção na ferramenta.
Recursos do Spark
Conectando-se a um servidor Openfire, os usuários do Spark podem trocar mensagens de texto, conversar por voz, enviar e receber arquivos e até enviar screenshots (imagens da tela/desktop) uns aos outros.
Vale a pena destacar também que o Spark suporta abas nas janelas de conversação e ainda permite que os usuários realizem conferências. Resumindo, são diversos recursos unidos ao ótimo desempenho e ao visual agradável.
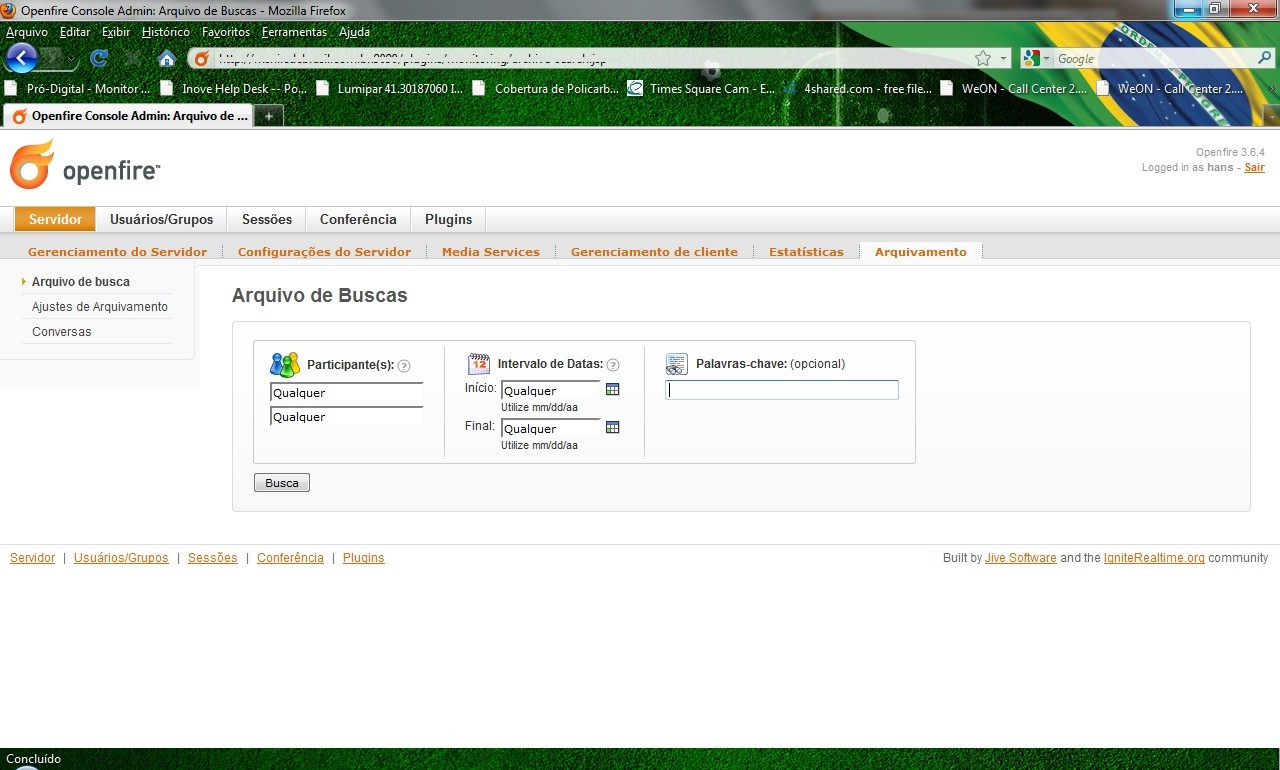
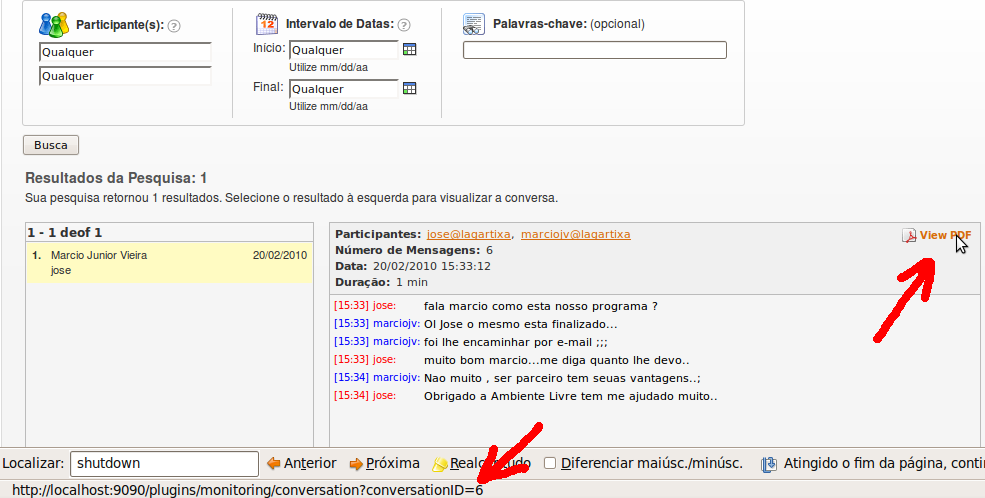
Tela de Buscas por palavras chaves de uma conversa
Vantagens e Características do Spark – OpenFire
– Google Talk
Este artigo mapear algumas das tabela relacionadas ao plugin Monitoring do OpenFire, com ele você pode descobrir como estão sendo armazenadas as informações de conversas no servidor de banco de dados HSQLDB, a consequentemente manipular estas informações quando necessário.
Primeiramente vamos configurar o ambiente para rodar o gerenciador gráfico do HSQLDB.
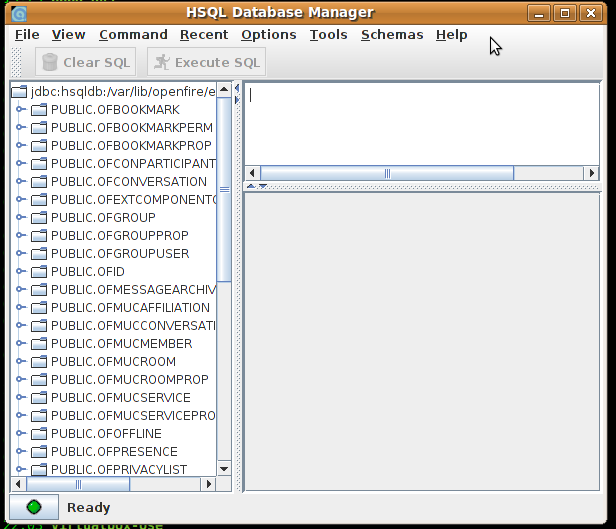
Tabela OfConversation – mostra estatisticas da conversa
CONVERSATIONID – Identificador único de cada conversar
ROOM – Sala de conversa
ISEXTERNAL –
STARTDATE – Data de Inicio da Conversa
LASTACTIVITY – Data de Inicio da Conversa
MESSAGECOUNT – Quantida de mensagem da conversa
Tabela Ofconparticipant – Conferências realizadas no OpenFire
CONVERSATIONID – Identificador único de cada conversar
JOINDATE –
LEFTDATE –
BAREJID –
JIDRESOURCE –
NICKNAME –
 Hoje estava ouvindo o quarto Episódio do OSBI Cast, o podcast da comunidade de BI Open Source um podcast de difusão de conhecimento e de divulgação da comunidade de Business Intelligence de Código Aberto. Composto com episódios mensais sempre com alguma personalidade da comunidade de BI e tomei conhecimento do que por meio do apoia-se se arrecadam fundos para manter a infraestrutura qualidade de sua edição, além de possibilitar a criação de mais quadros, ou seja, a geração de mais conteúdo. Hoje Mantido pelos hosts Fernando Maia da Mota e Fábio de Salles e a Vitrine Flávia Borato.
Hoje estava ouvindo o quarto Episódio do OSBI Cast, o podcast da comunidade de BI Open Source um podcast de difusão de conhecimento e de divulgação da comunidade de Business Intelligence de Código Aberto. Composto com episódios mensais sempre com alguma personalidade da comunidade de BI e tomei conhecimento do que por meio do apoia-se se arrecadam fundos para manter a infraestrutura qualidade de sua edição, além de possibilitar a criação de mais quadros, ou seja, a geração de mais conteúdo. Hoje Mantido pelos hosts Fernando Maia da Mota e Fábio de Salles e a Vitrine Flávia Borato.
Tive o primeiro contato quando abrimos um espaço no Pentaho Day 2019 em maio, para divulgar a iniciativa, a mesma “saiu do papel” e hoje já está em operação, o que me chamou a atenção é que havia apenas um apoiador (financeiro ao menos) desta campanha, por isso faço um apelo a quem acredita no desenvolvimento comunitário, que também são usuário de ferramentas open source de BI, ou já se beneficiou dos trabalhos comunitários de Fernando Maia (um plugin por exemplo: https://github.com/fernandommota/bootstrap-multiselect-pentaho-filter ) ou do Fábio Salles ( com os conteúdos do https://geekbi.wordpress.com/ ) , apoiem se possível a iniciativa OSBI Cast.
Os mesmos tem um excelente histórico colaborativo com a comunidade Pentaho e Open Source de BI em geral, e estão fazendo um excelente trabalho que está a disposição para toda a comunidade, e espero que inspire outras pessoas e profissionais a usarem ferramentas de Bi Open Source.
Então veja as formas de Apoiar!
Atualmente o mesmo tem duas categorias de apoio, o Apoio Entusiasta e o Apoio ouvinte frequente , que são apoios de R$ 2,00 ou mais ou R$ 10,00 respectivamente e mensalmente.
Eu fui o segundo apoiador espero que meu post influencie outras pessoas a ajudar pois a cultura no Brasil de apoios colaborativos sempre foi extremamente baixa e o uso de conteúdo e código compartilhado extremamente alto, ajude a melhorar esta balança e manter esta excelente iniciativa!
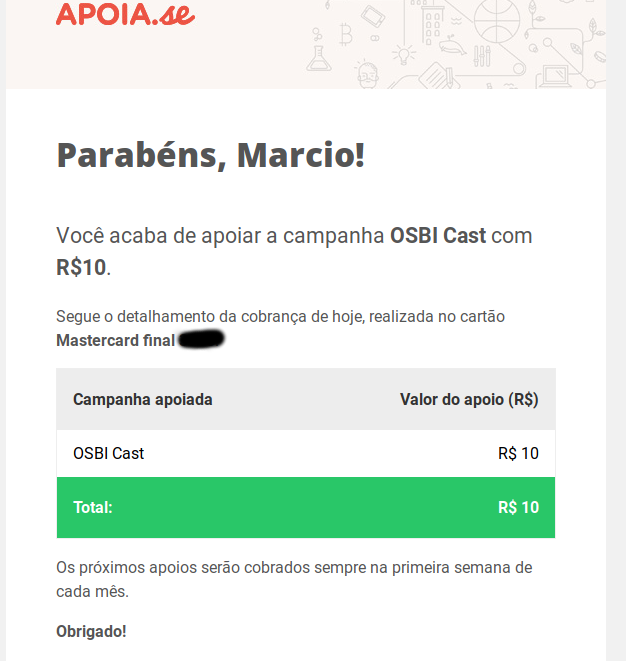
Links:
OSBI Cast : https://osbicast.com

A Sonda , empresa multinacional com sede central em Santiago, Chile, é um dos principais integradores e provedores de serviços de TI na América Latina, que em 2014 registrou receita líquida de US$ 1,447 bilhão e, após a aquisição da brasileira CTIS, atingiu a marca de 22 mil funcionários esta em busca de profissional Pentaho para atuação em projetos.
Requisitos da Vaga.
• Experiência na função de Analista ETL, modelagem e Analista BI
• Habilidade na reestruturação e modelagem de dados – tabelas e projetos, relacional ou multidimensional
• Conhecimentos em SQL (Oracle ou Sql Server)
• Sólida Experiência utilizando a ferramenta Pentaho
• Conhecimento de PL/SQL
Enviar o CV para recrutamentosp@sonda.com assunto “Vaga de Pentaho – São José dos Campos”
Para quem ainda não conhece Pentaho : http://www.ambientelivre.com.br/treinamento/pentaho/fundamental.html

Olá caros alunos de MBA (Positivo, FIAP, UniBrasil) e Alunos das formações de Big Data da Ambiente Livre e demais colegas da minha rede, mais uma vaga que podem interessar a vocês, esta aqui no nosso vale do Pinhão!
Um parceiro esta com vaga para atuação na capital paranaense. seguem dados para contato.


